- DataStream API 教程
- Setting up a Maven Project
- Writing a Flink Program
- Bonus Exercise: Running on a Cluster and Writing to Kafka
DataStream API 教程
In this guide we will start from scratch and go from setting up a Flink project to runninga streaming analysis program on a Flink cluster.
Wikipedia provides an IRC channel where all edits to the wiki are logged. We are going toread this channel in Flink and count the number of bytes that each user edits withina given window of time. This is easy enough to implement in a few minutes using Flink, but it willgive you a good foundation from which to start building more complex analysis programs on your own.
Setting up a Maven Project
We are going to use a Flink Maven Archetype for creating our project structure. Pleasesee Java API Quickstart for more detailsabout this. For our purposes, the command to run is this:
$ mvn archetype:generate \-DarchetypeGroupId=org.apache.flink \-DarchetypeArtifactId=flink-quickstart-java \-DarchetypeVersion=1.9.0 \-DgroupId=wiki-edits \-DartifactId=wiki-edits \-Dversion=0.1 \-Dpackage=wikiedits \-DinteractiveMode=false
You can edit the groupId, artifactId and package if you like. With the above parameters,Maven will create a project structure that looks like this:
$ tree wiki-editswiki-edits/├── pom.xml└── src└── main├── java│ └── wikiedits│ ├── BatchJob.java│ └── StreamingJob.java└── resources└── log4j.properties
There is our pom.xml file that already has the Flink dependencies added in the root directory andseveral example Flink programs in src/main/java. We can delete the example programs, sincewe are going to start from scratch:
$ rm wiki-edits/src/main/java/wikiedits/*.java
As a last step we need to add the Flink Wikipedia connector as a dependency so that we canuse it in our program. Edit the dependencies section of the pom.xml so that it looks like this:
<dependencies><dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java_2.11</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients_2.11</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-wikiedits_2.11</artifactId><version>${flink.version}</version></dependency></dependencies>
Notice the flink-connector-wikiedits2.11 dependency that was added. (This example andthe Wikipedia connector were inspired by the _Hello Samza example of Apache Samza.)
Writing a Flink Program
It’s coding time. Fire up your favorite IDE and import the Maven project or open a text editor andcreate the file src/main/java/wikiedits/WikipediaAnalysis.java:
package wikiedits;public class WikipediaAnalysis {public static void main(String[] args) throws Exception {}}
The program is very basic now, but we will fill it in as we go. Note that I’ll not giveimport statements here since IDEs can add them automatically. At the end of this section I’ll showthe complete code with import statements if you simply want to skip ahead and enter that in youreditor.
The first step in a Flink program is to create a StreamExecutionEnvironment(or ExecutionEnvironment if you are writing a batch job). This can be used to set executionparameters and create sources for reading from external systems. So let’s go ahead and addthis to the main method:
StreamExecutionEnvironment see = StreamExecutionEnvironment.getExecutionEnvironment();
Next we will create a source that reads from the Wikipedia IRC log:
DataStream<WikipediaEditEvent> edits = see.addSource(new WikipediaEditsSource());
This creates a DataStream of WikipediaEditEvent elements that we can further process. Forthe purposes of this example we are interested in determining the number of added or removedbytes that each user causes in a certain time window, let’s say five seconds. For this we firsthave to specify that we want to key the stream on the user name, that is to say that operationson this stream should take the user name into account. In our case the summation of edited bytes in the windowsshould be per unique user. For keying a Stream we have to provide a KeySelector, like this:
KeyedStream<WikipediaEditEvent, String> keyedEdits = edits.keyBy(new KeySelector<WikipediaEditEvent, String>() {@Overridepublic String getKey(WikipediaEditEvent event) {return event.getUser();}});
This gives us a Stream of WikipediaEditEvent that has a String key, the user name.We can now specify that we want to have windows imposed on this stream and compute aresult based on elements in these windows. A window specifies a slice of a Streamon which to perform a computation. Windows are required when computing aggregationson an infinite stream of elements. In our example we will saythat we want to aggregate the sum of edited bytes for every five seconds:
DataStream<Tuple2<String, Long>> result = keyedEdits.timeWindow(Time.seconds(5)).aggregate(new AggregateFunction<WikipediaEditEvent, Tuple2<String, Long>, Tuple2<String, Long>>() {@Overridepublic Tuple2<String, Long> createAccumulator() {return new Tuple2<>("", 0L);}@Overridepublic Tuple2<String, Long> add(WikipediaEditEvent value, Tuple2<String, Long> accumulator) {accumulator.f0 = value.getUser();accumulator.f1 += value.getByteDiff();return accumulator;}@Overridepublic Tuple2<String, Long> getResult(Tuple2<String, Long> accumulator) {return accumulator;}@Overridepublic Tuple2<String, Long> merge(Tuple2<String, Long> a, Tuple2<String, Long> b) {return new Tuple2<>(a.f0, a.f1 + b.f1);}});
The first call, .timeWindow(), specifies that we want to have tumbling (non-overlapping) windowsof five seconds. The second call specifies a Aggregate transformation on each window slice foreach unique key. In our case we start from an initial value of ("", 0L) and add to it the bytedifference of every edit in that time window for a user. The resulting Stream now containsa Tuple2<String, Long> for every user which gets emitted every five seconds.
The only thing left to do is print the stream to the console and start execution:
result.print();see.execute();
That last call is necessary to start the actual Flink job. All operations, such as creatingsources, transformations and sinks only build up a graph of internal operations. Only whenexecute() is called is this graph of operations thrown on a cluster or executed on your localmachine.
The complete code so far is this:
package wikiedits;import org.apache.flink.api.common.functions.AggregateFunction;import org.apache.flink.api.java.functions.KeySelector;import org.apache.flink.api.java.tuple.Tuple2;import org.apache.flink.streaming.api.datastream.DataStream;import org.apache.flink.streaming.api.datastream.KeyedStream;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import org.apache.flink.streaming.api.windowing.time.Time;import org.apache.flink.streaming.connectors.wikiedits.WikipediaEditEvent;import org.apache.flink.streaming.connectors.wikiedits.WikipediaEditsSource;public class WikipediaAnalysis {public static void main(String[] args) throws Exception {StreamExecutionEnvironment see = StreamExecutionEnvironment.getExecutionEnvironment();DataStream<WikipediaEditEvent> edits = see.addSource(new WikipediaEditsSource());KeyedStream<WikipediaEditEvent, String> keyedEdits = edits.keyBy(new KeySelector<WikipediaEditEvent, String>() {@Overridepublic String getKey(WikipediaEditEvent event) {return event.getUser();}});DataStream<Tuple2<String, Long>> result = keyedEdits.timeWindow(Time.seconds(5)).aggregate(new AggregateFunction<WikipediaEditEvent, Tuple2<String, Long>, Tuple2<String, Long>>() {@Overridepublic Tuple2<String, Long> createAccumulator() {return new Tuple2<>("", 0L);}@Overridepublic Tuple2<String, Long> add(WikipediaEditEvent value, Tuple2<String, Long> accumulator) {accumulator.f0 = value.getUser();accumulator.f1 += value.getByteDiff();return accumulator;}@Overridepublic Tuple2<String, Long> getResult(Tuple2<String, Long> accumulator) {return accumulator;}@Overridepublic Tuple2<String, Long> merge(Tuple2<String, Long> a, Tuple2<String, Long> b) {return new Tuple2<>(a.f0, a.f1 + b.f1);}});result.print();see.execute();}}
You can run this example in your IDE or on the command line, using Maven:
$ mvn clean package$ mvn exec:java -Dexec.mainClass=wikiedits.WikipediaAnalysis
The first command builds our project and the second executes our main class. The output should besimilar to this:
1> (Fenix down,114)6> (AnomieBOT,155)8> (BD2412bot,-3690)7> (IgnorantArmies,49)3> (Ckh3111,69)5> (Slade360,0)7> (Narutolovehinata5,2195)6> (Vuyisa2001,79)4> (Ms Sarah Welch,269)4> (KasparBot,-245)
The number in front of each line tells you on which parallel instance of the print sink the outputwas produced.
This should get you started with writing your own Flink programs. To learn moreyou can check out our guidesabout basic concepts and theDataStream API. Stickaround for the bonus exercise if you want to learn about setting up a Flink cluster onyour own machine and writing results to Kafka.
Bonus Exercise: Running on a Cluster and Writing to Kafka
Please follow our local setup tutorial for setting up a Flink distributionon your machine and refer to the Kafka quickstartfor setting up a Kafka installation before we proceed.
As a first step, we have to add the Flink Kafka connector as a dependency so that we canuse the Kafka sink. Add this to the pom.xml file in the dependencies section:
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka-0.11_2.11</artifactId><version>${flink.version}</version></dependency>
Next, we need to modify our program. We’ll remove the print() sink and instead use aKafka sink. The new code looks like this:
result.map(new MapFunction<Tuple2<String,Long>, String>() {@Overridepublic String map(Tuple2<String, Long> tuple) {return tuple.toString();}}).addSink(new FlinkKafkaProducer011<>("localhost:9092", "wiki-result", new SimpleStringSchema()));
The related classes also need to be imported:
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer011;import org.apache.flink.api.common.serialization.SimpleStringSchema;import org.apache.flink.api.common.functions.MapFunction;
Note how we first transform the Stream of Tuple2<String, Long> to a Stream of String usinga MapFunction. We are doing this because it is easier to write plain strings to Kafka. Then,we create a Kafka sink. You might have to adapt the hostname and port to your setup. "wiki-result"is the name of the Kafka stream that we are going to create next, before running our program.Build the project using Maven because we need the jar file for running on the cluster:
$ mvn clean package
The resulting jar file will be in the target subfolder: target/wiki-edits-0.1.jar. We’ll usethis later.
Now we are ready to launch a Flink cluster and run the program that writes to Kafka on it. Goto the location where you installed Flink and start a local cluster:
$ cd my/flink/directory$ bin/start-cluster.sh
We also have to create the Kafka Topic, so that our program can write to it:
$ cd my/kafka/directory$ bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic wiki-results
Now we are ready to run our jar file on the local Flink cluster:
$ cd my/flink/directory$ bin/flink run -c wikiedits.WikipediaAnalysis path/to/wikiedits-0.1.jar
The output of that command should look similar to this, if everything went according to plan:
03/08/2016 15:09:27 Job execution switched to status RUNNING.03/08/2016 15:09:27 Source: Custom Source(1/1) switched to SCHEDULED03/08/2016 15:09:27 Source: Custom Source(1/1) switched to DEPLOYING03/08/2016 15:09:27 Window(TumblingProcessingTimeWindows(5000), ProcessingTimeTrigger, AggregateFunction$3, PassThroughWindowFunction) -> Sink: Print to Std. Out (1/1) switched from CREATED to SCHEDULED03/08/2016 15:09:27 Window(TumblingProcessingTimeWindows(5000), ProcessingTimeTrigger, AggregateFunction$3, PassThroughWindowFunction) -> Sink: Print to Std. Out (1/1) switched from SCHEDULED to DEPLOYING03/08/2016 15:09:27 Window(TumblingProcessingTimeWindows(5000), ProcessingTimeTrigger, AggregateFunction$3, PassThroughWindowFunction) -> Sink: Print to Std. Out (1/1) switched from DEPLOYING to RUNNING03/08/2016 15:09:27 Source: Custom Source(1/1) switched to RUNNING
You can see how the individual operators start running. There are only two, becausethe operations after the window get folded into one operation for performance reasons. In Flinkwe call this chaining.
You can observe the output of the program by inspecting the Kafka topic using the Kafkaconsole consumer:
bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic wiki-result
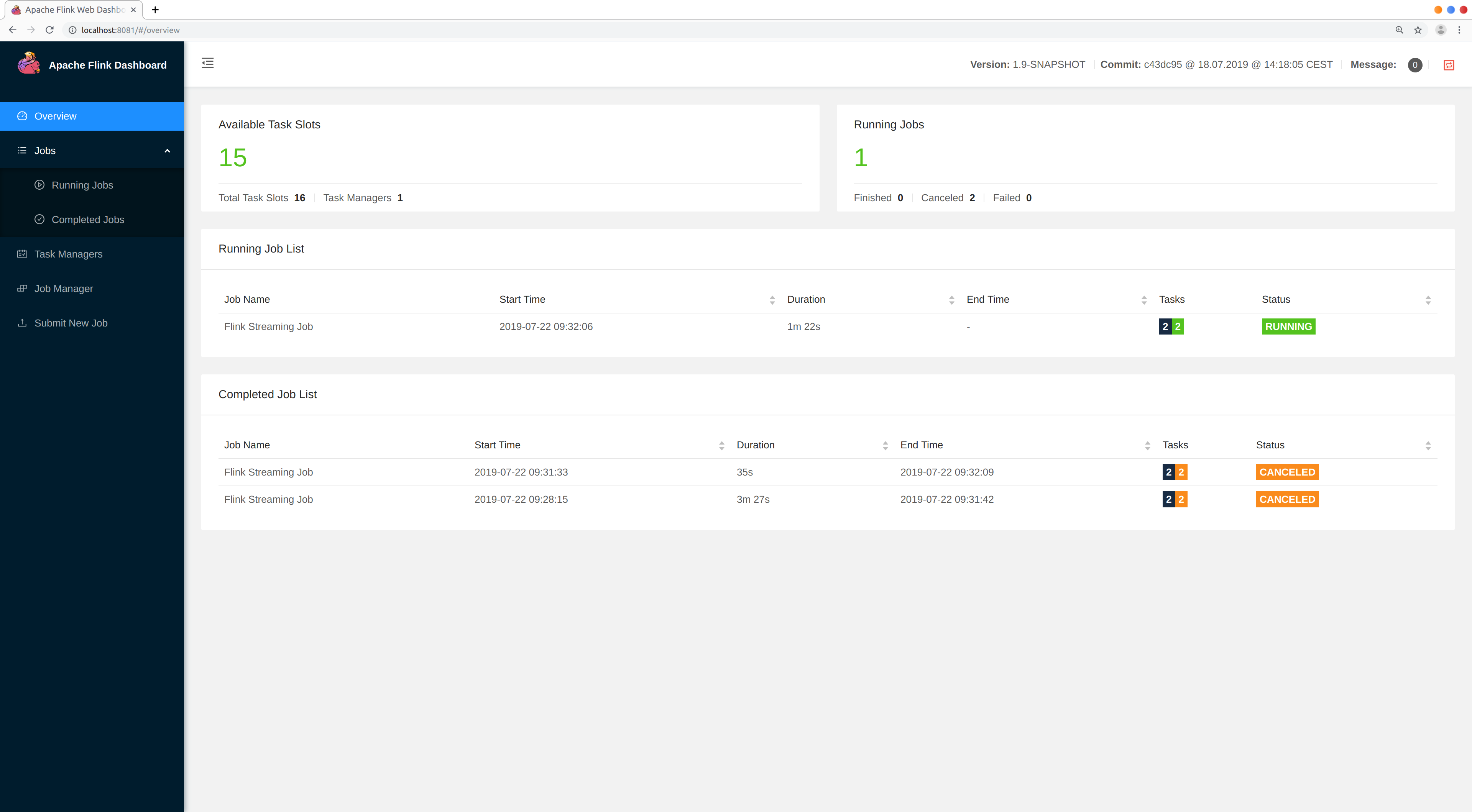
You can also check out the Flink dashboard which should be running at http://localhost:8081.You get an overview of your cluster resources and running jobs:
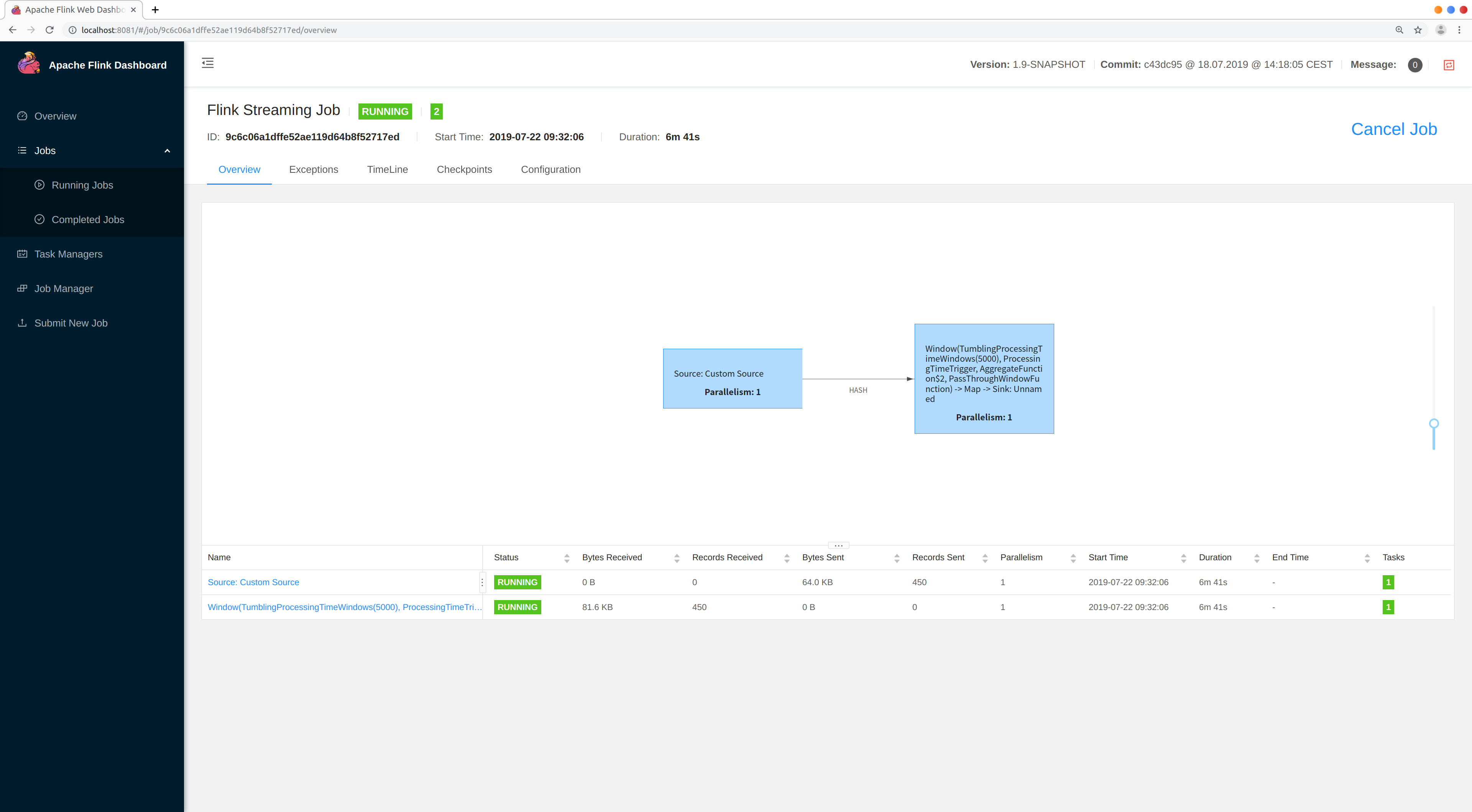
If you click on your running job you will get a view where you can inspect individual operationsand, for example, see the number of processed elements:
This concludes our little tour of Flink. If you have any questions, please don’t hesitate to ask on our Mailing Lists.
